IT之家 7 月 28 日新闻,Meta 宣布的一份研讨申报显示,其用于训练 4050 亿参数模子 Llama 3 的 16384 个英伟达 H100 显卡集群在 54 天内呈现了 419 次不测故障,均匀每三小时就有一次。此中,一半以上的故障是由显卡或其搭载的高带宽内存(HBM3)引起的。
因为体系范围伟大且义务高度同步,单个显卡故障可能导致整个训练义务中止,必要从新开端。只管如斯,Meta 团队照样坚持了 90% 以上的有用训练光阴。
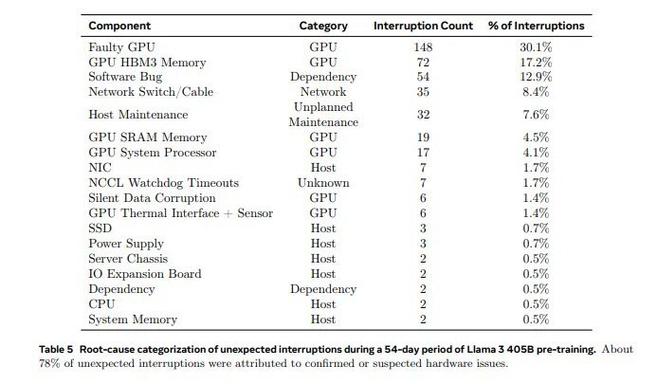
IT之家注意到,在为期 54 天的预预训练中,共呈现了 466 次事情中止,此中 47 次是方案中止,419 次是不测中止。方案内的中止是因为主动化维护造成的,而不测的中止则主要源于硬件问题。GPU 问题是导致故障的主要缘故原由,占不测中止的 58.7%。此中只有三发难件必要年夜量人工干涉,别的的由主动化治理。
在 419 个不测中止中,148 个(30.1%)是由各类 GPU 故障(包含 NVLink 故障)引起的,而 72 个(17.2%)是由 GPU 的 HBM3 内存故障引起的。有趣的是,54 天内只有两个 CPU 产生故障。41.3% 的不测中止是由多种因素造成的,包含软件差错、收集电缆和收集适配器。
为进步效力,Meta 团队开发了一系列对象和优化策略,包含缩短义务启动和反省点光阴、应用 PyTorch 的 NCCL 飞行记载器诊断机能问题、辨认拖后显卡等。此外,Meta 还存眷到了情况因素的影响,如午间温度颠簸对 GPU 机能的稍微影响,以及巨量 GPU 同时运行对数据中心电网的伟大压力。
然而,跟着人工智能模子参数目的赓续增长,所需的计算资本也随之扩展。以 xAI 方案中的 10 万块 H100 显卡集群为例,故障率可能会成倍增加,给将来的 AI 训练带来更年夜的挑战。















